
Word embedding - Nhúng từ là một trong những kĩ thuật được sử dụng nhiều nhất trong các bài toán xử lí ngôn ngữ tự nhiên NLP. Hoàn toàn có thể khẳng định rằng sự thành công của các mô hình học sâu tân tiến nhất trong NLP chính là một phần nhờ vào kĩ thuật nhúng từ. Trong bài viết này mình sẽ chia sẻ lại việc tìm hiểu về word embedding và implement một vài mô hình học sâu nổi tiếng để thực hiện kĩ thuật này.
Text Representation
Ai cũng hiểu rằng máy tính chỉ có thể hiểu được các con số chứ không phải từ ngữ như con người. Vì vậy để máy tính có thể xử lí được các tác vụ liên quan đến ngôn ngữ hay cụ thể hơn là để xây dựng bộ dữ liệu để huấn luyện các mô hình học máy, học sâu cho các bài toán NLP việc cần phải làm là biểu diễn các từ ngữ dưới dạng con số. Một cách phổ biến để thực hiện điều này là biểu diễn từ dưới dạng one-hot vector.
One-Hot Encoding
One-Hot Encoding là cách biểu diễn dữ liệu dưới dạng one-hot vector - là vector toàn giá trị 0 và chỉ có duy nhất một giá trị 1. Đối với đầu vào là các đoạn văn bản thì việc đầu tiên cần phải làm là phải xử lí đoạn văn bản (text preprocessing) và xây dựng một từ điển là các từ được xuất hiện trong văn bản đó, như vậy các từ sẽ được map với các vị trị khác nhau. Sau khi có được từ điển này thì one-hot vector của một từ được xây dựng bằng cách tạo ra một vector có chiều dài bằng với kích thước của từ điển (số các từ trong từ điển) và đặt giá trị 1 tại giá trị vị trị của từ đó trong từ điển và 0 tại các vị trí còn lại.
Ví dụ như từ điển ta xây dựng được chứa 1000 từ được map với giá trị vị trí của nó:
{'as': 0,'abashed': 1,'abide': 2,...,'crew': 100,'cried': 101,...,'zero': 999}
Như vậy, one-hot vector của từ 'abashed' tại vị trị thứ 2 là:
[0,1,0,0,...,0,0]
Hay one-hot vector của từ 'zero' tại vị trí cuối cùng là:
[0,0,0,0,...,0,1]
Sau khi xây dựng được các one-hot vector cho tất cả các từ trong từ điển thì máy tính đã có thể hiểu được và ta đã có thể mang đi huấn luyện cho các mô hình học máy. Tuy nhiên, các bài toán về NLP vì dụ như bài toán dịch máy thì một từ có mối quan hệ về ngữ nghĩa với nhiều từ khác mà one-hot vector không thể hiện được. Ngoài ra, thông thường bộ từ điển các từ sẽ rất lớn (có thể lên đến hàng triệu từ) điều này kéo theo kích thước của one-hot vector cũng rất lớn. Tệ hơn nữa, khi ta gặp các từ mới ta phải chèn thêm cột vào vector, đồng nghĩa với việc ta phải thêm các trọng số mới cho mô hình, gây khó khăn cho quá trình huấn luyện. Đây chính là lí do mà người ta sẽ sử dụng kĩ thuật nhúng từ để giải quyết các nhược điểm này.
Word Embedding
Word Embedding nhúng từ cũng là một kĩ thuật để biểu diễn từ dưới dạng các vector số học, nhưng điểm khác biệt đó là đây là các continuous vector và các vector này có thể học được! Bằng cách sử dụng continuous vector thì ta đã có thể thể hiện sự tương quan giữa các từ. Ví dụ trong câu "I like eating apple and banana", khi đổi chỗ "apple" và "banana" thì câu không thay đổi về mặt ngữ nghĩa nên 2 từ này có sự tương quan về mặt ngữ nghĩa và cả về ngữ pháp khi cả hai đều là danh từ. Hoặc như giữa "banana" và "yellow" cũng có sự tương quan nhất định khi quả chuối thường có màu vàng. Đã có nhiều thuật toán được đưa ra để xây dựng lên các vector đại diện cho các từ này. Tuy nhiên bài viết này chỉ cập đến phương pháp sử dụng mạn nơ-ron, cụ thể là:
Feedforward Neural Net Language Model
Rõ ràng có thể thấy với các phương pháp thống kê để nhúng tù gặp phải một nhược điểm là khi chiều (kích thước) của vector đại diện lớn thì việc tính toán sẽ rất phức tạp. Năm 2003, Bengio đã đề xuất sử dụng những đặc điểm của mạng trí tuệ nhân tạo và xây dựng một mô hình với mục tiêu là giải quyết được vấn đề kể trên. Mạng này sẽ nhận đầu vào là từ trước đó và dự đoán ra từ tiếp theo hợp lí nhất (N-Gram). Kiến trúc mạng được đề xuất trong bài báo như sau:
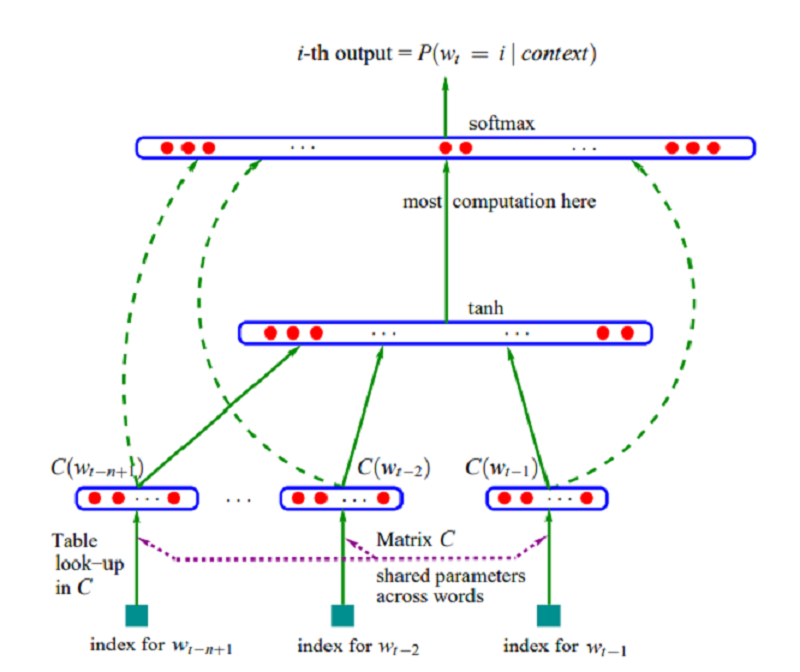
Cụ thể mạng có 3 thành phần chính:
- Một lớp embedding nhằm tạo ra vector nhúng từ bằng cách nhân one-hot vector với ma trận nhúng từ
- Các lớp ẩn (hidden layer) có thể một hoặc nhiều lớp, đầu ra được đưa vào các hàm phi tuyến (trong bài báo là hàm tanh)
- Hàm softmax ở cuối cùng tạo ra phân phối xác suất cho các từ trong từ điển.
Để có thể dễ hiểu hoạt động của mạng hơn ta sẽ đi xây dựng mạng với Pytorch.
Theo như hình cấu trúc mạng ở trên trên, từ sau khi qua lớp embedding ta sẽ thu được các vector nhúng từ e(x) với kích thước là (1 x embedding_dim), sau đó các vector này sẽ được ghép lại với nhau thành vector x' có kích thước (1 x (context_size x embedding_dim)), trong nội dung bài viết context_size = 2 (Tri-Gram) tức dùng 2 từ trước đó để dự đoán 1 từ tiếp theo. Qua các lớp ẩn thứ nhất thu được h = tanh(W1*x'+b1) và đầu ra thu được là y = softmax(W2*h + W3*x' + b)
Implement mạng như sau:
class NNLM(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size, h):
super(NNLM, self).__init__()
self.embedding_dim = embedding_dim
self.context_size = context_size
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.hidden1 = nn.Linear(context_size * embedding_dim, h)
self.hidden2 = nn.Linear(h, vocab_size)
self.hidden3 = nn.Linear(context_size*embedding_dim, vocab_size)
def forward(self, inputs):
embeds = self.embeddings(inputs).view(-1, self.context_size * self.embedding_dim) # concat
output = torch.tanh(self.hidden1(embeds))
output = self.hidden2(output) + self.hidden3(embeds)
log_probabilities = F.log_softmax(output, dim=1)
return log_probabilities
Tiếp theo, ta sẽ xây dựng tập dữ liệu huấn luyện cho mô hình, ta dùng 2 từ trước đó (từ bối cảnh) để dữ đoán từ tiếp theo (từ mục tiêu) và loại bỏ hết các câu có độ dài nhỏ hơn 3.
# create train set with context size = 2
def create_nnlm_trainset(sentence_list, word2index_dict):
contexts = []
targets = []
for sentence in sentence_list:
word_list = sentence.split()
for i, word in enumerate(word_list):
if i+2 >= len(word_list):
break
contexts.append([word2index_dict.get(word), word2index_dict.get(word_list[i+1])])
targets.append([word2index_dict.get(word_list[i+2])])
x_train = np.array(contexts)
y_train = np.array(targets)
train_set = np.concatenate((x_train, y_train), axis=1)
return train_set
train_set = np.asarray(create_nnlm_trainset(sentence_list, word2index_dict))
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
Hàm loss ta sử dụng là negative log likelihood và optimizer là SGD với learning_rate = 0.002
loss_function = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=0.002)
Cuối cùng, ta sẽ huấn luyện mạng.
EPOCHS = 1000
train_loss_list = []
train_acc_list = []
for epoch in range(EPOCHS):
st = time.time()
for i, data in enumerate(train_loader):
context_tensor = data[:,0:2].to(device)
target_tensor = data[:,2].to(device)
model.zero_grad()
log_probs = model(context_tensor)
probs = torch.exp(log_probs)
#acc calculatation
predictions = torch.argmax(probs, dim=1)
acc = (predictions == target_tensor).float().mean()
loss = loss_function(log_probs, target_tensor)
loss.backward()
optimizer.step()
train_loss_list.append(loss.item())
train_acc_list.append(acc)
if (epoch+1) % 100 == 0:
print(f'\n------ Training NNLM model at epoch {epoch+1} ------')
print(f"Loss: {loss.item()}, Acc: {acc}, Time (s): {time.time()-st}")
st = time.time()
Khi quá trình huấn luyện kết thúc thì trọng số của lớp embedding chính là ma trận nhúng từ mà ta cần. Ví dụ vector nhúng từ của từ 'princess' trong từ điển.
# embedding of "princess"
print(model.embeddings.weight[word2index_dict["princess"]])
Output:
tensor([-1.1004, -0.7284, -1.6246, -1.0463, 1.5166, -2.0885, -0.4297, -1.6749,
-1.4178, -0.3732, -0.3640, -2.6313, -1.9372, 0.3845, 1.3074, 0.1530,
0.8196, -1.0368, -0.0687, 2.6086, 0.5552, 0.0839, -0.5072, -2.0082,
-0.9646, 0.2489, 1.0137, -0.7822, -0.1682, -1.0961], device='cuda:0',
grad_fn=<SelectBackward>)
Đó là cách ma trận nhúng từ được xây dựng. Có thể thấy mạng dự báo càng chuẩn thì vector nhúng sẽ càng thể hiện chính xác sự tương quan giữa các từ bối cảnh và từ mục tiêu. Mặc dù mục đích của mạng là dự đoán từ mục tiêu từ các từ bối cảnh nhưng thực chất sau khi huấn luyện xong chúng ta chỉ quan tâm đến trọng số của lớp embedding. Đây còn được gọi là "the fake task". Tuy nhiên có thể thấy nhược điểm của NNLM đó là chi phí tính toán rất lớn, cụ thể là ở lớp tính sofmax cuối cùng, đặc biệt là với bộ từ vựng lớn.
Word2Vec
Nếu như NNLM là mạng đầu tiền áp dụng trí tuệ nhân tạo cho việc tạo ra các vector nhúng từ thì word2vec là mô hình thực hiện việc nhúng từ phổ biến nhất. Được giới thiệu bởi Mikolov vào năm 2013, trong bài báo đầu tiên tác giả đã giới thiệu 2 kiến trúc mạng để học ma trận nhúng từ, đặc điểm của hai mạng này là chi phí tính toán sẽ giảm so với NNLM. Tiếp theo ở bài báo thứ 2 tác giả đã đưa ra các giải pháp để cải thiện tốc độ huấn luyện và độ chính xác của mô hình. Hai cấu trúc được giới thiệu đó là:
- Continuous Bag-Of-Words (CBOW)
- Skip-gram
CBOW
Như ở trên thì NNLM chỉ sử dung những từ ở quá khứ để làm bối cảnh dự đoán cho từ mục tiêu, mặc dù những từ bối cảnh ở phía sau từ mục tiêu cũng có những sự liên quan nhất định. Vì vậy Mikolov đã sử dụng từ trước và từ sau của từ mục tiêu cho việc dữ đoán. Đó là lí do nó được gọi là continuous bag-of-words vì nó sử dụng các từ liên tiếp mà không quan tâm đến thứ tự của các từ đó.
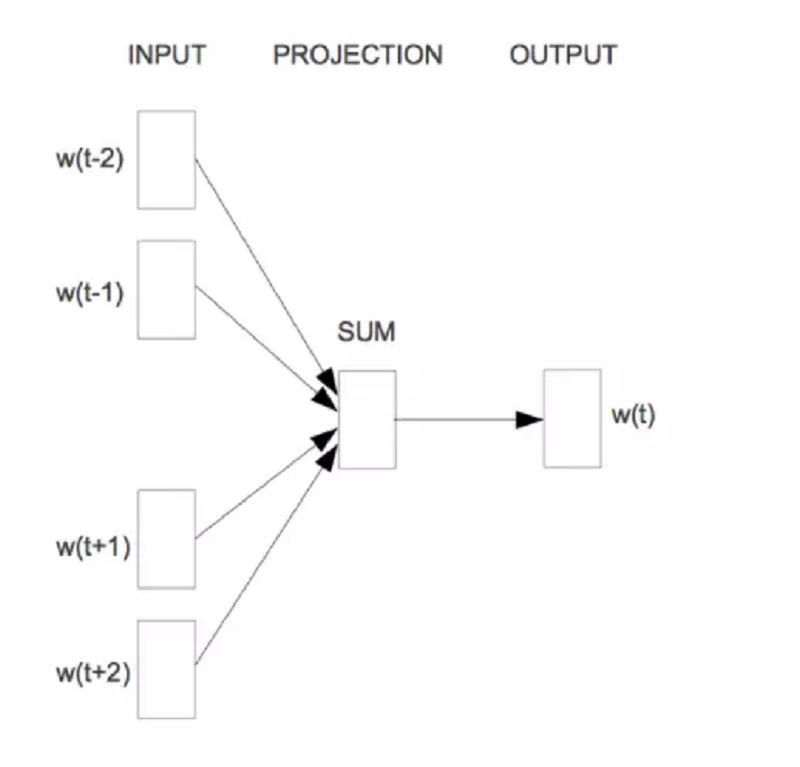
SkipGram
Ngược lại với CBOW thì SkipGram sẽ đưa vào một từ và dự đoán các từ xung quanh từ đó. Ví dụ câu "I like eating apple and banana", từ bối cảnh sẽ là "apple" còn các từ mục tiêu là "like", "eating", "and", "banana" (2 từ trước và 2 từ sau)
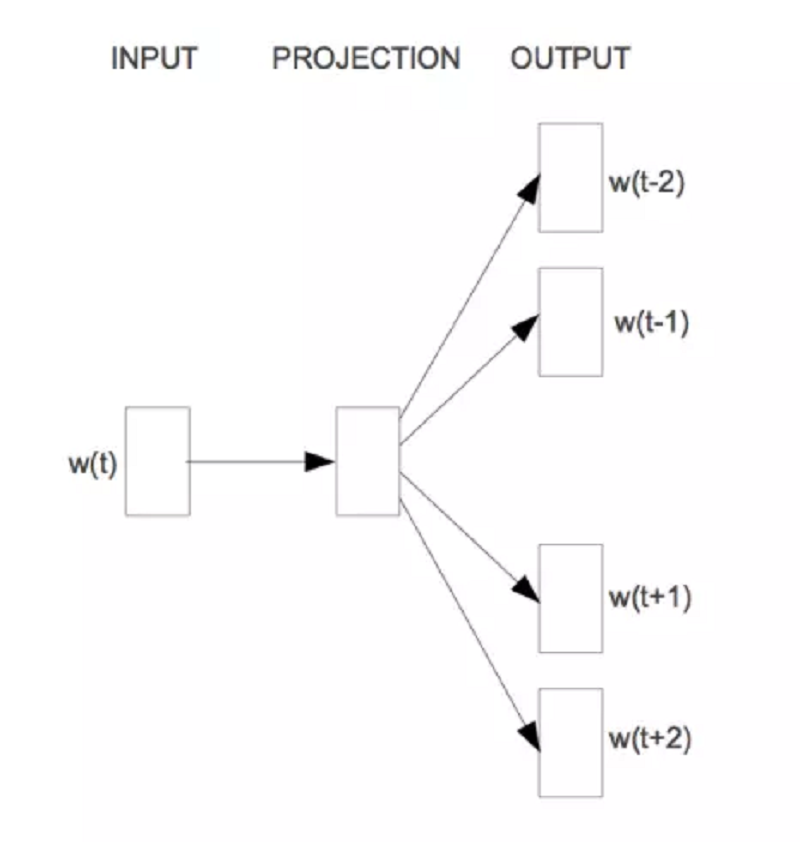
Điều nổi bật ở đây là tác giả đã đề xuất một vài cách để giảm chi phí tính toán (như đã nói nhược điểm của softmax ở đầu ra). Một trong những cách đó là Negative Sampling. Cụ thể, tác giả biến bài toán thành nhận biết với từ bối cảnh đầu vào thì từ mục tiêu dự đoán có đúng hay không. Như ví dụ ở trên, cặp "apple" và "like" được coi là positive sample (có 4 cặp positive sample), ghép "apple" với một từ khác trong từ điển như "dog" ta thu được một cặp negative sample. Tỉ lệ giữa positive sample và negative sample thường là 1:2~5 cho những đoạn văn bản lớn và 1:5~20 cho đoạn văn bản nhỏ. Như vậy với negative sampling bài toán trở thành phân loại nhị phân!
Note: phần implement của 2 mô hình CBOW và SkipGram mình sẽ để ở Colab Notebook này!
Nguồn: Do Dang Hung (viblo.asia)

