
Bí kíp tối ưu hoá (optimize) code C/C++
“Optimize code” là gì ?
“Optimize code” là việc sử dụng một số kỹ thuật và phương pháp để code hoặc sửa đổi code sẵn có (legacy code) nhằm mục đích nâng cao chất lượng và hiệu năng của chương trình. Tùy vào từng ngữ cảnh cụ thể mà “Optimize code” có thể được thực hiện để làm cho chương trình/phần mềm trở nên:
- Chạy nhanh hơn.
- Sử dụng ít tài nguyên (CPU, memory) hơn.
- Kích thước chương trình (code size) nhỏ hơn.
- Dễ bảo trì, dễ đáp ứng với sửa đổi hơn.
Lưu ý rằng chúng ta không thể đồng thời đạt được những điều trên. Ví dụ: một chương trình sử dụng ít tài nguyên đôi khi sẽ chạy chậm hơn và ngược lại. Việc lựa chọn mục tiêu và phương pháp tối ưu phụ thuộc vào từng bài toán cụ thể.
Optimize code được chia thành 2 cấp độ là high-level và low-level.
- Tối ưu ở cấp độ high-level được thực hiện thủ công bởi lập trình viên, họ sẽ sử dụng các kỹ thuật tối ưu vào việc xây dựng các hàm, lớp, các vòng lặp…
- Tối ưu ở mức độ low-level được thực hiện tự động bởi trình biên dịch, nó được thực hiện khi trình biên dịch dịch C/C++ source code sang ngôn ngữ máy.
Trong phạm vi bài viết này chúng ta sẽ chỉ đề cập đến optimize code thủ công ở cấp độ high-level (cấp độ thiết thực nhất, liên quan trực tiếp đến các anh em dev) và tạm thời để các vấn đề liên quan đến optimize cấp độ low-level sang một bên.
Mặt trái của “Optimize code”
Bất cứ cái gì cũng có 2 mặt và “optimize code” cũng không phải ngoại lệ. Code được optimized quá nhiều thường sẽ khó đọc, khó sử dụng lại, khó bảo trì và khó debug. Vì vậy không phải lúc nào “optimize code” cũng tốt. Optimize code có tốt hay không ? có cần thiết hay không ? còn tùy thuộc vào từng trường hợp, từng ngữ cảnh cụ thể.
Công cụ đo hiệu năng của chương trình
Công cụ đo hiệu năng chương trình là thứ không thể thiếu khi chúng ta optimize code. Bởi vì chúng ta cần phải cụ thể hóa các thông số về việc sử dụng CPU, sử dụng memory…làm cơ sở để đánh giá kết quả của việc optimize. Nếu không có nó chúng ta sẽ không thể biết được việc optimize của chúng ta có tác dụng hay không ? đạt được mục tiêu đề ra chưa ?
Có một số tools hay được sử dụng với chương trình C/C++ như sau
- Trên Windows:
- Visual Studio Performance Profiler: Tool này được tích hợp sẵn trên Visual Studio từ version 2010 trở đi.
- Trên Linux:
- Perf
- Valgrind
Trong phạm vi bài viết này mình chỉ đưa ra tên của các tools, cụ thể cách sử dụng ra sao anh em tự tìm hiểu nhé.
Các bí kíp optimize code
Bây giờ chúng ta sẽ cùng nhau tìm hiểu về các phương pháp, kỹ thuật thường được áp dụng để optimize code.
Sắp xếp thứ tự các điều kiện trong câu lệnh ‘if’ một cách hợp lý
a) Nếu xác xuất nhận giá trị true/false của các điều kiện con bên trong là tương đương nhau thì nên đặt các điều kiện đơn giản, có thời gian xử lý nhanh lên trước, đặt các điều kiện phức tạp, có thời gian xử lý lâu hơn ở phía sau. Ví dụ:

Giả sử chúng ta quy ước như sau
- Điều kiện A: (a == 1) –> Thời gian xử lý để check điều kiện A là T1
- Điều kiện B:(objectB.getValue() == 2) –> Thời gian xử lý để check điều kiện B là T2
Giả sử thời gian kiểm tra điều kiện B là đáng kể hơn so với thời gian kiểm tra điều kiện A vì để kiểm tra điều kiện B thì cần phải gọi hàm objectB.getValue() để lấy kết quả ra thực hiện phép toán so sánh. Tức là T2 lớn hơn T1 khá nhiều (T2 >> T1).
Nếu đặt điều kiện B lên trước thì:
- Nếu B false thì (A && B) sẽ nhận giá trị false bất kể A true hay false→ Chương trình sẽ không cần thực hiện kiểm tra điều kiện A nữa → Tổng thời gian check điều kiện là T2
- Nếu B true thì chương trình vẫn cần phải kiểm tra thêm cả điều kiện A → Tổng thời gian check điều kiện là (T1 + T2)
Nếu đặt điều kiện A lên trước thì:
- Nếu A false thì (A && B) sẽ false bất kể B true hay false. Khi đó chương trình sẽ không cần thực hiện kiểm tra điều kiện B, do đó tiết kiệm được thời gian xử lý → Tổng thời gian check điều kiện là T1
- Nếu A true thì chương trình vẫn cần phải kiểm tra cả điều kiện B → Tổng thời gian check điều kiện là (T1 + T2)
Như vậy ta có thể thấy đặt điều kiện A lên trước (như hình bên phải) sẽ có lợi hơn.
b) Nếu xác suất nhận giá trị true/false của các điều kiện con bên trong là chênh lệch nhau thì
- Với phép “AND”, ví dụ (A && B): Nên đặt điều kiện có xác suất nhận giá trị false nhiều hơn lên trước.
- Với phép “OR”, ví dụ (A || B): Nên đặt điều kiện có xác suất nhận giá trị true nhiều hơn lên trước
Nếu có thể hãy sử dụng ‘switch’ thay vì một loạt các lệnh ‘if’
Câu lệnh switch sử dụng jump table để nhảy đến đoạn code cần thực hiện thay vì check từng điều kiện như một loạt các lệnh if. Chính vì vậy sử dụng lệnh switch sẽ giúp chương trình chạy nhanh hơn so với việc sử dụng nhiều lệnh if → Bất cứ khi nào có thể thay nhiều lệnh if bằng lệnh switch thì hãy sử dụng lệnh switch.
Bên dưới đây là một ví dụ →

Sử dụng lookup table thay cho câu lệnh switch
Trong một số trường hợp sử dụng lookup table thay cho câu lệnh switch sẽ làm tăng khả năng maintain và làm chương trình nhỏ gọn hơn. Ví dụ →

Khi code sử dụng lookup table như hình bên phải thì chương trình sẽ nhỏ gọn hơn và khi cần thêm một giá trị mới thì chỉ cần add thêm 1 giá trị vào mảng Greek.
Tối ưu phạm vi của biến
a) Nếu biến là một đối tượng của một class và được sử dụng bên trong vòng lặp nhưng không bị thay đổi trong vòng lặp thì nên khai báo biến ngay trước vòng lặp. Điều này là để tránh việc hàm khởi tạo và hàm hủy của đối tượng được gọi liên tục một cách không cần thiết trong mỗi lần lặp. Ví dụ →

b) Trường hợp không liên quan đến vòng lặp và biến chỉ được sử dụng ở trong một phạm vi cục bộ nào đó thì nên khai báo biến trong phạm vi nhỏ nhất mà nó được sử dụng. Ví dụ →

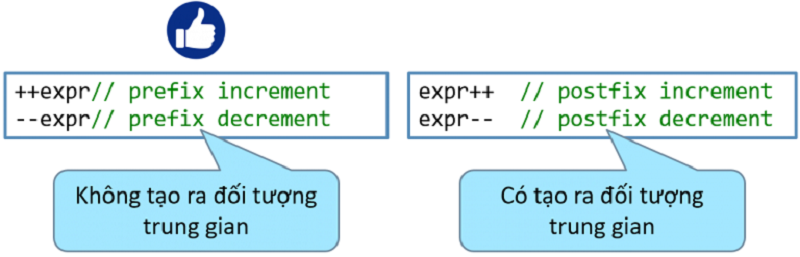
Sử dụng toán tử tăng/giảm một cách hợp lý
Khi sử dụng toán tử tăng/giảm ở dạng hậu tố thì khi chạy chương trình sẽ tạo ra đối tượng trung gian, do đó làm tăng thời gian xử lý (do phải gọi hàm copy constructor và hàm hủy), thời gian xử lý đó sẽ khá đáng kể với những biến là đối tượng của class. Vì vậy nên sử dụng toán tử tăng/giảm ở dạng tiền tố thay vì hậu tố trong trường hợp giá trị của biểu thức không được sử dụng. Ví dụ →
Nên sử dụng toán tử gán kết hợp toán tử số học thay vì sử dụng toán tử toán học và toán tử gán riêng biệt
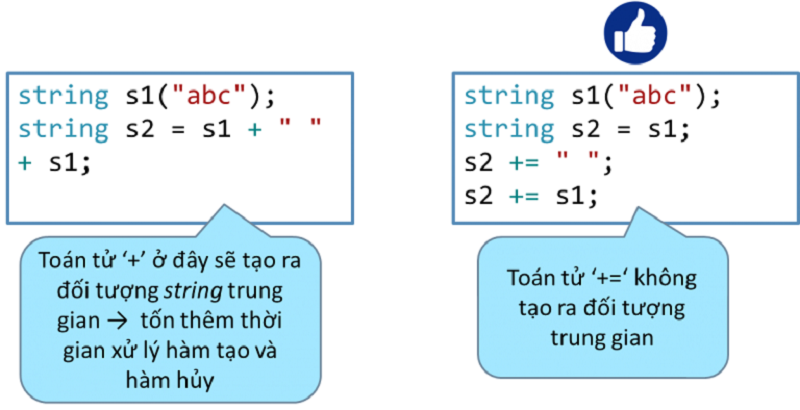
Khi khởi tạo đối tượng, nên sử dụng hàm khởi tạo thay vì toán tử gán
Ví dụ →

Chú ý về việc sử dụng hàm inline
Ví dụ về hàm inline →

Đặc điểm và nguyên tắc sử dụng hàm inline →
- Sử dụng hàm inline sẽ làm tăng performance, thời gian thực thi của hàm sẽ nhanh hơn. Để rõ hơn tại sao nhanh hơn thì tham khảo link sau: https://www.cppdeveloper.com/c-co-ban/3-7-3-ham-noi-tuyen/
- Tuy nhiên khi đó mã máy sẽ bị trùng rất nhiều (do trình biên dịch đặt một bản sao code của hàm đó tại mỗi vị trí mà hàm đó được gọi tại thời điểm biên dịch), dẫn đến kích thước chương trình sẽ tăng lên.
- Chỉ nên sử dụng hàm inline với các hàm nhỏ:
- Theo kinh nghiệm của mỗ là <= 5 line of code
- Không có vòng lặp
Nguyên tắc truyền tham số cho hàm
Khi truyền một biến x có kiểu dữ liệu là T vào một hàm như là tham số func thì nên tuân theo nguyên tắc sau:
- Nếu x là tham số chỉ dùng để đọc (input-only):
- Nếu x có kích thước lớn và có thể nhận giá trị NULL → Truyền bằng con trỏ trỏ tới hằng số: func(const T* x);
- Nếu x có kích thước lớn nhưng không thể nhận giá trị NULL → Truyền bằng tham chiếu hằng số: func(const T& x);
- Các trường hợp khác → Truyền bằng giá trị hằng số: func(const T x);
- Nếu x là tham số dùng để output hoặc cả input và output
- Nếu x có thể NULL → Truyền bằng con trỏ: func(T* x);
- Nếu x không thể nhận giá trị NULL → Truyền bằng tham chiếu: func(T& x);
Kỹ thuật internal cache trong function
Nếu một hàm phải thực hiện tính toán phức tạp, tốn thời gian thì nên cân nhắc sử dụng cơ chế cache ngay trong hàm sử dụng các biến static để tạo cache. Ví dụ →

Trong ví dụ trên thì phần code bên phải sử dụng biến static để xử lý cache, tăng performance của hàm.
Tránh sử dụng object làm giá trị trả về của hàm
Kiểu dữ liệu trả về của một hàm nên là kiểu dữ liệu đơn giản (int, float, char. ..), là còn trỏ, là tham chiếu hoặc void. Hàm trả về một đối tượng của class sẽ làm mọi chuyện trở nên phức tạp và không hiệu quả. Khi kết quả trả về là một đối tượng có thể dẫn đến việc sinh ra các đối tượng trung gian không cần thiết làm tốn thêm thời gian xử lý. Ví dụ →

Lưu ý rằng hiện nay, hầu hết các trình biên dịch đều tự động tối ưu cho các trường hợp trả về một đối tượng như ở trên để giúp cho performance của chương trình không bị ảnh hưởng. Tuy nhiên trình biên dịch là một thứ gì đó không cố định, có thể trình biên dịch này xử lý thế này nhưng trình biện dịch khác lại xử lý khác, tốt nhất chúng ta nên tự làm thế nào để code chạy ngon mà không phụ thuộc nhiều vào trình biên dịch.
Sử dụng hàm thành viên static
Trong các class, với các hàm thành viên không truy cập vào biến non-static thì nên implement các hàm đó dưới dạng hàm static. Bởi vì khi call hàm static thì không cần truyền tham số ngầm định this vào cho hàm, điều đó giúp tiết kiệm memory và giảm thời gian xử lý. Ví dụ →

Hàm plus của class A nên được implement ở dạng hàm static do nó không truy cập bất kỳ biến thành viên nào của class.
Sử dụng Constructor Initialization List
Trong hàm khởi tạo của class, đối với các biến thành viên có kiểu dữ liệu là class thì tốt nhất là nên khởi tạo chúng trong cái gọi là Constructor Initialization List thay vì gán giá trị cho biến đó bên trong hàm khởi tạo. Ví dụ →

Việc khởi tạo cho biến a như hình đoạn code bên trái sẽ tốn 2 công đoạn, đầu tiên là khởi tạo a với hàm khởi tạo mặc định của nó, sau đó gán cho nó giá trị là “value”. Tuy nhiên nếu code theo như đoạn code bên phải thì biến a sẽ được khởi tạo luôn chỉ với một lần call hàm khởi tạo 1 tham số, nhờ đó rút ngắn được thời gian xử lý.
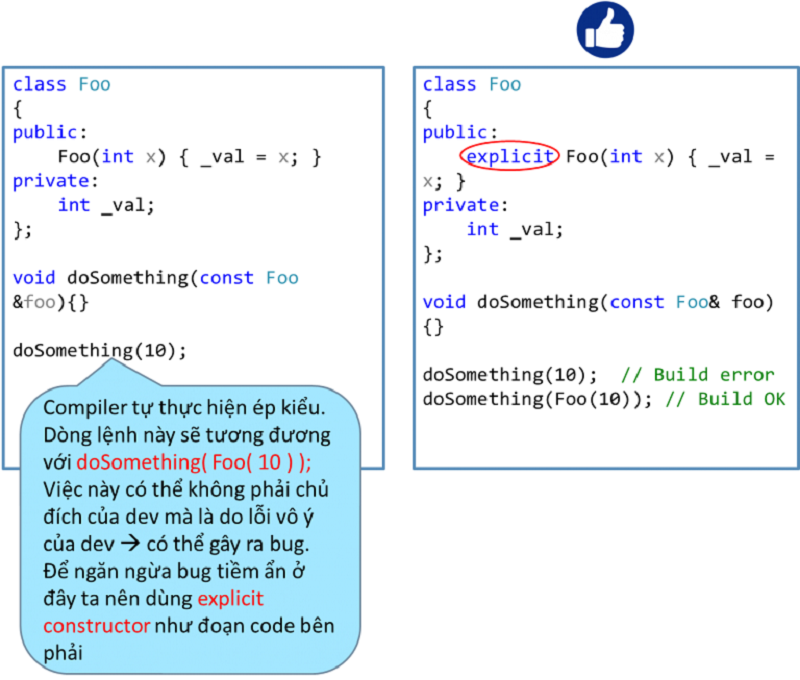
Nên sử dụng explicit constructor đối với hàm khởi tạo một tham số
Nên sử dụng explicit constructor đối với tất cả hàm khởi tạo một tham số, ngoại trừ copy constructor.
Ví dụ →
Nguyên tắc khi sử dụng “smart pointers”
Smart pointer là gì ? →
- Là 1 class wrap lại raw pointer của C++
- Mục đích chính của việc sử dụng smart pointer là để đảm bảo đối tượng được xóa và memory được giải phóng khi đối tượng không còn được sử dụng nữa. → Tóm lại là ngăn ngừa leak memory.
- Có 3 loại smart pointers trên C++11:
- unique_ptr: Không làm giảm performance khi sử dụng
- shared_ptr: Làm giảm performance khi sử dụng
- weak_ptr: Làm giảm performance khi sử dụng
Chính vì sử dụng smart pointer có thể làm giảm performance nên cần phải cẩn thận khi sử dụng, không sử dụng bừa bãi. Vậy khi nào nên/không nên sử dụng smart pointer ? Hãy xem →
- Nếu việc cấp phát và giải phóng đối tượng / memory là do cùng 1 hàm hoặc một class chịu trách nhiệm thì không cần thiết phải sử dụng smart pointer.
- Chỉ nên sử dụng smart pointer trong trường hợp một đối tượng / memory được cấp phát bởi một hàm và sau đó bị xóa bởi một hàm khác và hai hàm này không liên quan đến nhau (không phải là hàm thành viên của cùng một class)
Truy cập bộ nhớ theo chiều thứ tự tăng dần của địa chỉ
Thực tế cho thấy bộ nhớ cache của CPU hoạt động hiệu quả nhất khi dữ liệu được truy cập tuần tự theo chiều thứ tự tăng dần của địa chỉ. Nó hoạt động kém hiệu quả khi dữ liệu được truy cập ngược và ít hiệu quả hơn nữa khi dữ liệu được truy cập một cách ngẫu nhiên. Điều này áp dụng cho việc đọc cũng như ghi dữ liệu. Chính vì vậy nên truy cập bộ nhớ theo chiều thứ tự tăng dần của địa chỉ. Ví dụ →
Nên scan mảng một chiều theo thứ tự index tăng dần →

Nên scan mảng nhiều chiều theo nguyên tắc rightmost index cho innermost loops. Tức là vòng lặp trong cùng thì tương ứng với index ngoài cùng bên phải và cứ như vậy cho đến vòng lặp ngoài cùng và index trong cùng vên trái. Nói thì loằng ngoằng, xem code hiểu ngay →

Nên truy cập biến member của class theo thứ tự khai báo của chúng →

Chọn chế độ đọc/ghi file hợp lý
Đọc/ghi file ở binary mode thì nhanh hơn đọc/ghi file ở text mode. Chính vì vậy, trong trường hợp sử dụng mode nào cũng được thì nên đọc/ghi file ở binary mode.
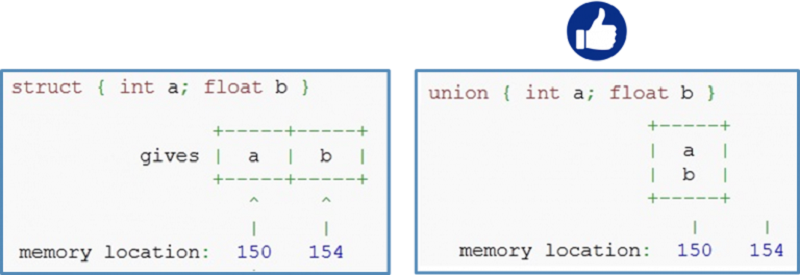
Sử dụng union để tiết kiệm bộ nhớ
Nếu 2 hoặc nhiều biến thành viên của structure không bao giờ được sử dụng cùng một thời điểm thì nên sử dụng union thay vì struct để chia sẻ vùng nhớ giữa các biến này → tiết kiệm bộ nhớ.
Ví dụ → Nếu 2 biến thành viên a và b không bao giờ cần sử dụng cùng một thời điểm thì nên sử dụng union thay vì struct
Phương pháp sắp xếp các trường dữ liệu của structure để tiết kiệm bộ nhớ
Nên sắp xếp các biến thành viên của class/structure từ trên xuống dưới theo chiều giảm dần của kích thước, điều đó sẽ giúp làm giảm kích thước của class/structure. Hãy xem ví dụ sau, anh em sẽ hiểu tại sao →
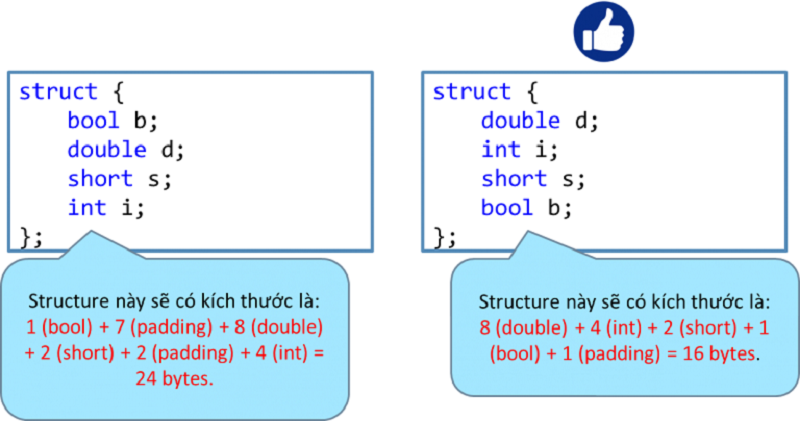
Để rõ hơn về cách tính kích thước của structure, hãy tham khảo link sau: https://www.cppdeveloper.com/best-practices/data-alignment-trong-c-c/
Không nên sử dụng ‘bitfields’ nếu muốn tăng performance
Bitfields có thể được sử dụng để làm cho data nhỏ gọn và dễ truy cập hơn. Ví dụ →

Với cách khai báo như ở trên thì chúng ta có thể truy cập và sử dụng một số bit riêng lẻ trong 1 byte một cách dễ dàng. Tuy nhiên truy cập biến thành viên của bitfield thì chậm hơn so với truy cập biến thành viên của structure. Chính vì thế không nên sử dụng kỹ thuật ‘bitfields’ nếu muốn tăng performance.
Sử dụng ‘worker thread’ cho những task tính toán xử lý tốn thời gian
Với các appliation yêu cầu thời gian đáp ứng với action của người dùng nhanh, độ trễ thấp thì tất cả các công việc tính toán, xử lý nặng, tốn thời gian cần phải được tách ra chạy trên các threads riêng gọi là các worker threads. Và các worker threads phải có độ ưu tiên thấp hơn độ ưu tiên của GUI thread. Tư tưởng như sau →
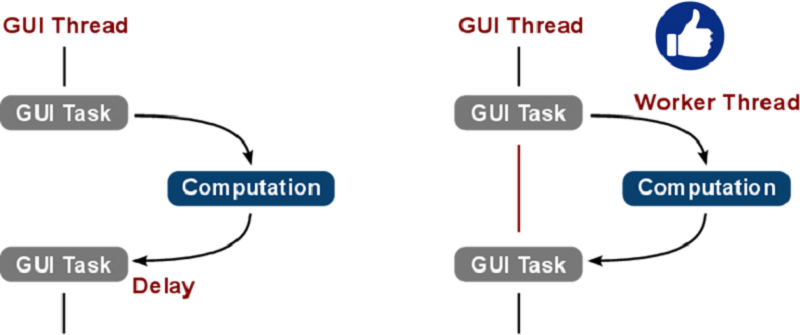
Kết
Trên đây là một số kỹ thuật, tips/tricks trong việc optimize C/C++ code mà mình thấy là gần gũi nhất và trên thực tế mình cũng thường apply vào trong công việc. Thực ra vấn đề về optimization này khá là rộng, mình không thể nói hết trong một bài được và mình cũng ko đủ trình để biết hết tất cả. Chỉ mong rằng anh em có thể học và áp dụng được phần nào đó vào công việc để tăng level và value của bản thân, kiếm nhiều xèng hơn. Chúc anh em code vui vẻ !

Nguồn: cppdeveloper.com

